"Introduction: deep learning for speech recognition"
Deep learning for speech recognition blog series: Introduction
This is the first in a series of posts documenting my process in setting up a deep learning speech recognition system described by Zhang et al. (2017) in Julia using the Flux machine learning package for my Google Summer of Code 2018 project. A note on these posts, I wrote the bulk of them on the date that I have written for them. However, some of them are published on subsequent days, and I may update them from time to time.
My Google Summer of Code 2018 project centers around developing a Julia implementation of the aforementioned system described by Zhang et al. (2017) using the Flux library. It will be contributed to the model zoo at the end of it. I believe this is important work because speech recognition is popular right now, and the model zoo does not yet have a model that does automatic speech recognition. This is not a problem unique to Flux, however, because there are few easily accessible deep neural network code implementations of speech recognition systems.
This series is not intended to be an introduction to deep learning per se, but rather, an introduction to using deep learning techniques for speech recognition. It is targeted toward those who know about deep learning generally, but are relative newcomers to speech and speech data. I will attempt to reference relevant introductory material when relevant, however. Additionally, I will be using a mostly APA-style citation format when I make references to documents, articles, tutorials, books, etc. You are under no obligation to read through them if what I've written seems clear, but if you find something confusing or are simply curious, the citations are there for you.
If you are in need of an introduction to deep learning, there are a number of resources available. My personal favorite is Deep Learning with Python (Chollet, 2017), and there is also a version of it for R called Deep Learning with R (Chollet & Allaire, 2018). For those who wish to delve more deeply into the mathematical and theoretical underpinnings of deep learning, there is the Deep Learning book (Goodfellow, Bendio, & Courville), though in my opinion, it is not for the faint of heart and nor particularly compelling for a front-to-back reading. Practical examples of deep learning can be found on the Machine Learning Mastery website (Brownlee, 2018), and build-up of theory into application on the MNIST data set is available in the [Neural Netowrks and Deep Learning online book[(http://neuralnetworksanddeeplearning.com) (Nielson, 2015).
All right. So, presuming that you're at least familiar with deep learning concepts (you don't need to be a pro; I don't consider myself to be, either), you should be prepared to read this series. Broadly, the series will consist of an introduction to speech data and different ways to represent them (which is what this post is), a discussion of the network architecture, a tutorial on the connectionist temporal classification loss function (as described in Graves et al. (2006) and Graves (2012)), and finally a discussion of the activation functions and an overall description of the finished network.
But, that's enough of the formalities. Let's get started with this entry's topic: speech. I will begin by describing the process of speaking up until producing an acoustic signal, then I will briefly discuss different approaches to analyzing that acoustic signal, and I will conclude with a code demonstration of extracting the speech features that I will be using in the speech recognition model I'm implementing.
Once you have read this entry in the series, you should have enough domain knowledge to begin building the speech recognition system and hopefully be able to search for other resources to satisfy any curiosities you have. Additionally, I hope you will come away with a greater appreciation for the complexity of speech and the automatic speech recognition problem domain. Finally, and perhaps most importantly, you should have the skills to extract speech features using the Julia programming language and relevant software packages.
Speech
The act of producing speech is one of those activities we engage in virtually every day in hearing communities. It feels natural, and on the surface, it seems quite simple. On further inspection, however, it is remarkably complex and involves the coordination of a great number of body parts and mental processes. (Note that I will not be attending much to the human mental processes here, as they seem to be largely irrelevant to the engineering of an accurate speech recognition model on computers.)
The physiological aspects of speech
Putting aside cognitive processes, speech begins in the lungs. The diaphgragm contracts to expel air from the lungs up into the vocal tract. At the beginning of the vocal tract is the larynx, containing the glottis, itself containing the vocal folds (which are casually referred to as vocal cords). The vocal folds open and close to modulate the flow of air through the vocal folds. This modulated air then makes its way up through the trachea, past the epiglottis and pharynx, and into the oral and nasal cavities. A diagram of the vocal tract may be seen in Figure 1.
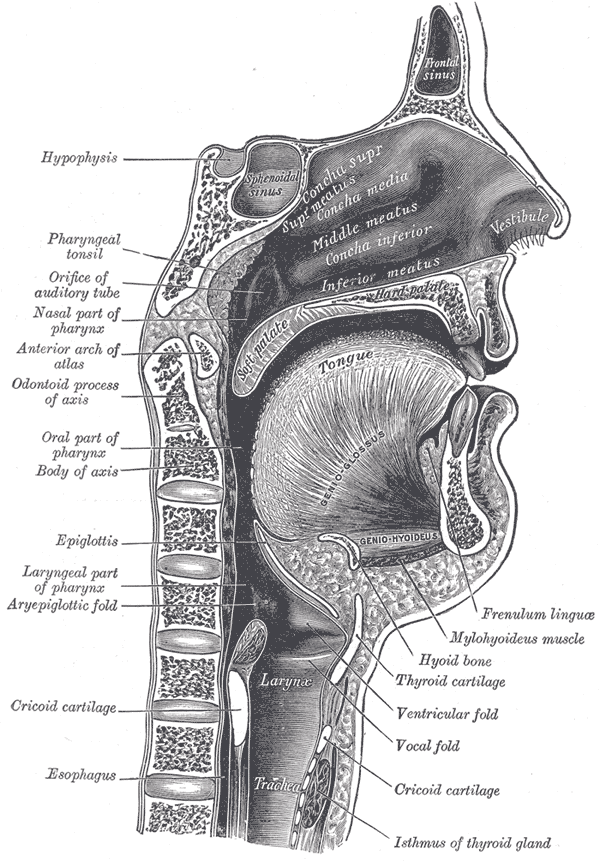
Figure 1: Sagittal view of the mouth and vocal tract from Grey's Anatomy 1918 edition, as presented by the Wikipedia page on the vocal tract (Wikipedia contributors, 2018d). Image in the public domain.
From the time at which the air stream is in the glottis up until it leaves the body, movable organs may intervene and shape the air stream. These movements have different effects on the acoustic signal, which will be discussed in a subsequent section. Linguists (phoneticians in particular) and speech scientists have identified these organs that are involved in the articulation of speech, and we call them articulators. The movements of the articulators in the process of speaking is complex, and they move in a continuous (as opposed to discrete) fashion. In ultrasounds and MRIs of the oral cavity, the tongue can be seen darting from corner to corner of the mouth, taking on a variety of shapes and making contact with many different regions of the mouth. There are a handful of videos of MRI and ulstrasound imaging on the tongue on YouTube, such as this one. (The audio and video get slowed down considerably to show the articulations, at the cost of the audio becoming a bit creepy-sounding.)
In spite of the continuous nature of the orchestra of articulator movements, though, researchers have catalogued many attested common movement patterns, which are referred to as speech segments or phones. They are described in three dimensions: their voicing, their place of articulation, and their manner of articulation. In an articulatory sense, voicing refers to whether the vocal folds are vibrating while the segment is being articulated. The phone [z] at the start of the word zoo is voiced (as is the vowel component), and you can feel this if you place your hand on your throat while speaking the word. The place of articulation is, as the name suggests, the place in the vocal tract where a particular phone is realized. Using the example of [z] again, it is articulated with the tongue at the alveolar ridge, so we say it is an alveolar sound. The manner of articulation describes how a phone is realized. The phone [z] is realized as a fricative, meaning that there is a place of constriction and the air stream is fricated as it passes through the constriction. Together, these three dimensions describe the phone [z], which is referred to as a voiced alveolar fricative.
The International Phonetic Alphabet (International Phonetic Association, 1999), commonly referred to as the IPA, catalogs the phones that have been found across the world's languages. The Wikipedia page on the IPA (Wikipedia contributors, 2018a) is informative, and it has links to pages with recordings of most of the sounds. With this alphabet that relates to articulation, researchers who work with or reason about speech data (like speech scientists, linguists (especially phoneticians and phonologists), and speech pathologists) can create transcriptions of speech events that are much better at describing the actual speech event than orthographic representations.
To summarize this section on the articulation of speech, the speech process begins with forcing air from the lungs. This stream of air is shpaed on its way out of the body by movements of different speech organs called articulators. There are observable patterns ißn the movement of these articulators, which researchers refer to as speech segments or phones. And, phones are important because they provide a way of transcribing a speech event that is better related to the speech event than spelling is. If you are interested in reading more on articulation, the book Articulatory Phonetics (Gick, Wilson, & Derrick, 2013) should be a good choice.
The idea of these transcription tools is important for our purposes because they are used widely across speech recognition system as the targets to identify in the speech stream, which is possible because these articulations ultimately result in differences in the acoustic signal produced. The next section gives an overview of how speech produces an acoustic signal, which is ultimately the bassis of speech recognition.
References
Brownlee, J. (2018). Machine learning mastery. Retrieved May 26, 2018, from https://machinelearningmastery.com/.
Chollet, F. (2017). Deep learning with Python. New York: Manning Publications.
Chollet, F., & Allaire, J. J. (2018). Deep Learning with R. New York: Manning Publications.
Goodfellow, I., Bengio, Y., Courville, A., & Bengio, Y. (2016). Deep learning. Cambridge: MIT Press.
Graves, A. (2012). Supervised sequence labelling with recurrent neural networks. Berlin: Springer. Preprint available at https://www.cs.toronto.edu/~graves/preprint.pdf.
Graves, A., Fernández, S., Gomez, F., & Schmidhuber, J. (2006, June). Connectionist temporal classification: Labelling unsegmented sequence data with recurrent neural networks. In Proceedings of the 23rd international conference on machine learning (pp. 369-376). ACM.
Nielson, M. A. (2015). Neural networks and deep learning. Determination Press. Retrieved May 26, 2018 from http://neuralnetworksanddeeplearning.com/.
Wikipedia contributors. (2017, December 5). Bark scale. In Wikipedia, the free encyclopedia. Retrieved May 26, 2018, from https://en.wikipedia.org/w/index.php?title=Bark_scale&oldid=813742442.
Zhang, Y., Pezeshki, M., Brakel, P., Zhang, S., Bengio, C. L. Y., & Courville, A. (2017). Towards end-to-end speech recognition with deep convolutional neural networks. arXiv preprint arXiv:1701.02720.